Rao-Blackwellized Score Matching on Manifolds
Figuring out what denoising score matching actually learns when data is drawn from a low-dimensional structure in a high-dimensional space [arXiv]
(Part of a series of short writeups covering recent work.)
A lot of modern machine learning assumes the manifold hypothesis: the assumption that the data we care about has some structure to it (formally, this means that it lies on or near some manifold). Under the manifold hypothesis, score matching (a widely used method for learning a data distribution) is fundamentally ill-posed. As a result, practitioners use a variant known as denoising score matching, which resolves the ill-posedness problem, but doesn't necessarily guarantee that we learn the right data distribution. In this work, we examine what exactly is learned by denoising score matching.
- We show that the tangent DSM target has a fundamental singularity on manifolds: the normal-fiber noise variance diverges as as .
- We show that conditioning on the nearest-point projection canonically removes this singularity, giving the unique -optimal Rao-Blackwellized predictor of the tangent denoising target.
- We compute the small-noise expansion of this canonical target and show it equals plus an explicit correction decomposing into an intrinsic Tweedie term and an extrinsic curvature term involving the Weingarten and Ricci operators.
- On the correction reduces to ; on the extrinsic term cancels exactly, though the Tweedie correction remains.
Background
Score Matching
A lot of times, we want to learn a data distribution, but we can't because computing the partition function1 is intractable. So, instead of matching the distribution's values at every point in the domain, we instead match the gradient [Hyv05] (this gets rid of our partition function problem because the partition function is independent of the coordinate ). This works fantastically for general data, but if we constrain our data to lie on some low dimensional structure, things fall apart rather quickly. Since the probability distribution is nonzero on the manifold, but zero right off the manifold, we have points at which the derivative does not exist and score matching is not well defined. To get around this, we add noise to the data so that it no longer lies exactly on the manifold.2
Denoising score matching. The practical way to do this is denoising score matching (DSM): we take a clean sample (here is our data distribution defined on the manifold), corrupt it with Gaussian noise to get for , and train a network to regress against the denoising direction . By Tweedie's formula [Efr11], minimizing this regression loss recovers the score of the noisy density , and as , this converges to the score of itself. When is a nice density on , we are done: DSM gives you the score up to a smoothing bias.
But under the manifold hypothesis the ambient score doesn't exist at all ( has no density w.r.t. the Lebesgue measure), so there is nothing to take the gradient of. DSM at is still a well-defined regression problem, it's just not clear what exactly it's estimating. To start thinking about this, it's helpful to split the denoising direction at each noisy point into pieces along and orthogonal to the manifold (denoted from here on out) at the nearest projection . The normal piece is just , a deterministic function of -- so it contains no information about where actually came from on . All the signal lives in the tangent piece:
This leaves a few questions open: what is actually estimating? Does it converge to the intrinsic Riemannian score ? Does it even have a sensible variance as ?
In order to answer these, we'll need to set up a bit of differential geometry.
Differential Geometry
Differential geometry is concerned with differentiable manifolds: geometric structures that, when we zoom in enough, look like regular flat (Euclidean) space.3 For example, a plane embedded in a three-dimensional space is a manifold. A plane is a special type of manifold since it doesn't have any curvature: most manifolds have two notions of curvature.
Curvature. Extrinsic curvature tells us how bends inside the ambient . Intrinsic curvature is inherent to and requires no knowledge of the embedding in ambient space. Both end up as linear maps on the tangent space, so we may compare them directly.
At each , the ambient space splits as , with orthogonal projections and .
Second fundamental form, Weingarten operator, and mean curvature. Consider traveling along in some tangent direction . The velocity vector can't stay constant in ; the manifold is curving, so must bend. The part of that bending that points normal to is the second fundamental form: , a symmetric bilinear map on . It's a super clean object for measuring extrinsic curvature since it directly measures how tangent directions get pushed off the manifold. The Weingarten operator is the exact same information, just in the form of a linear map. For each normal direction , define by . acts on tangent vectors, so we can apply it directly to things like -- which is what shows up in the result. The mean curvature vector is the trace of : for any orthonormal basis of (the sum is basis-independent). This points in the direction is curving "on average."
Ricci endomorphism. Now, let us turn to intrinsic curvature; ignoring the embedding entirely. If we live on , we can still measure curvature directly by noticing things like how geodesics4 spread apart. The Ricci endomorphism packages this intrinsic curvature into a linear operator on the tangent space.5Gauss equation. Intrinsic and extrinsic curvature are actually linked: the metric on is induced from the ambient inner product. The exact relationship is given by the Gauss equation , where is any orthonormal basis of . The takeaway is that intrinsic curvature is determined by the embedding: it's the mean-curvature Weingarten minus a separate "sum of squared Weingartens" contribution.
Rao-Blackwellization and the Nearest-Point Projection
Having established our machinery, we may now return to the question we really care about: what is actually estimating, and can we control its variance?
The classical statistics move here is Rao-Blackwellization. The Rao-Blackwell Theorem tells us that conditioning an unbiased estimator on a sufficient statistic can only reduce its variance. Intuitively, we keep the expected value, but integrate out the part of the noise that doesn't carry any signal. The natural thing to condition on in our setting is the nearest-point projection . It captures the manifold-valued summary of the noisy observation -- "where on did likely come from" -- and discards the normal offset, which by construction carries no information about . Formally, among all fiber-collapsing summaries -- statistics depending on only through , i.e. -- the projection is the finest. Anything coarser throws away information that retains.
Define the Rao-Blackwellized tangent target: . From the Pythagorean identity for projections, we can show that among all functions of , the choice minimizes the regression risk:
Thus, is the unique (up to null sets) -optimal target in this class, and the excess risk of any coarser estimator decomposes into the irreducible "noise" part and a separable "estimator error" part. Intuitively, keeps all the signal-bearing information in and averages out the rest.
Variance Collapse
Okay, so we found the -optimal target, now we want to know if it actually buys us anything quantitatively. The answer is a resounding yes.The conditional variance of given is the irreducible portion that can't be removed by any fiber-collapsing summary, and we can write it down exactly:
Theorem 1 (Variance collapse under Rao-Blackwellization). Uniformly in , . Consequently , while .
The intuition for the is pretty straightforward. Conditioned on , the latent is concentrated on within a tangent ball of radius around (this is just the posterior of given ). So has typical tangent magnitude , and dividing by gives a typical magnitude of . Squaring and summing over the tangent dimensions gives . So, as we shrink the noise, the variance of grows, which is exactly the opposite of what we want from a regression target.
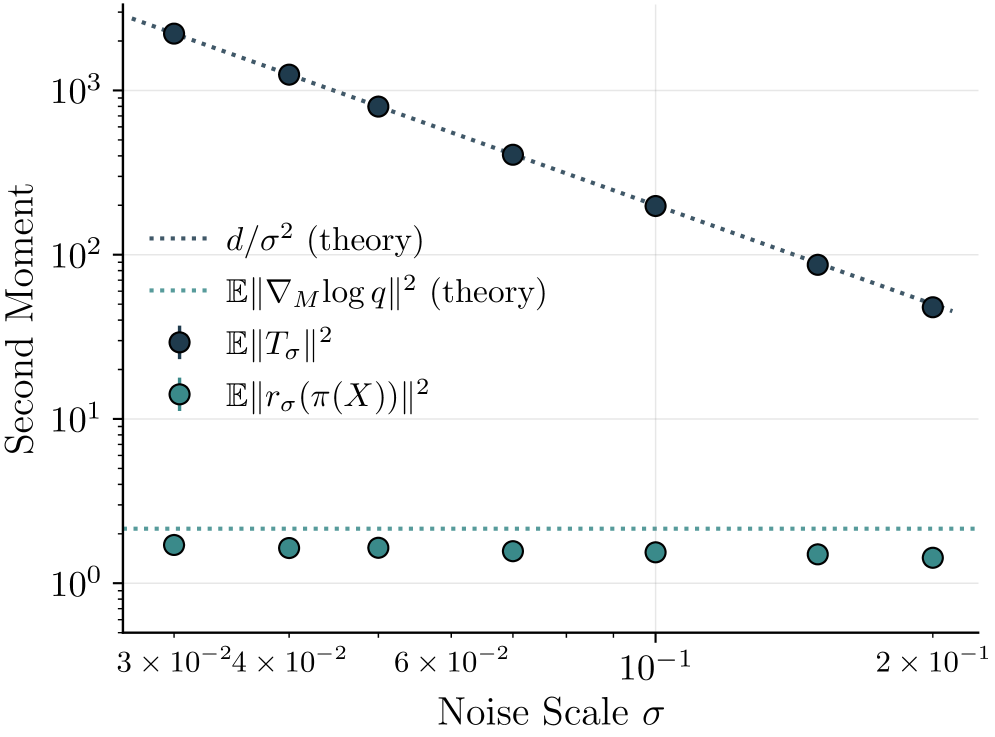
The floor isn't just a property of our particular estimator -- it's an irreducible Bayes-risk floor for any fiber-collapsing summary. That is, for any statistic with , the best possible predictor of based on has expected squared error at least . Coarsening doesn't help; only the projection itself achieves the floor exactly.
Correction
Now that we have a target with bounded variance, the natural next question is what it actually equals. Expanding as a power series in : uniformly on .
The leading term is the intrinsic Riemannian score -- exactly what fully-intrinsic methods regress against. So at leading order, ambient DSM (after the Rao-Blackwellization fix) recovers the right thing. The correction is more interesting. It splits into two distinct pieces:
- The intrinsic Tweedie bias . This is the manifold analog of the flat-Tweedie bias: it comes from Gaussian smoothing of the density and would appear even on a flat support. It depends on but not on the embedding, and it's the same correction you'd get from intrinsic methods.
- The extrinsic curvature term . This piece matters for non-flat manifolds. It depends on the embedding of in via the Weingarten and Ricci operators defined before. It's invisible to any method that corrupts by intrinsic Riemannian noise -- intrinsic noise never leaves the manifold, and thus never feels the embedding.
A nice property of is that the operator is purely geometric -- it depends only on how sits in , not on . So if we've trained a score model , we can apply this operator to our model's output and subtract times the result. The correction is fully post-hoc; you don't need to re-train, and you don't need to know .6
Cancellation
On , , , , and . Plugging in: So on the sphere, the extrinsic correction is a scalar multiple of the intrinsic score, with coefficient :
- : ;
- : ;
- : ;
- : increasingly negative.
On , the extrinsic curvature correction vanishes identically, and ambient DSM recovers the intrinsic score up to only the flat-Tweedie bias .
It's worth emphasizing that this is a coincidence specific to the round sphere, not a general 2-manifold property. The torus is intrinsically flat () but extrinsically curved, and the corresponding has coefficient -- a measurable embedding-only bias. Higher-dimensional spheres also show the bias clearly: on and , raw ambient DSM under-concentrates the equilibrium distribution by about 17% and 33% respectively, both removed by the post-hoc correction.
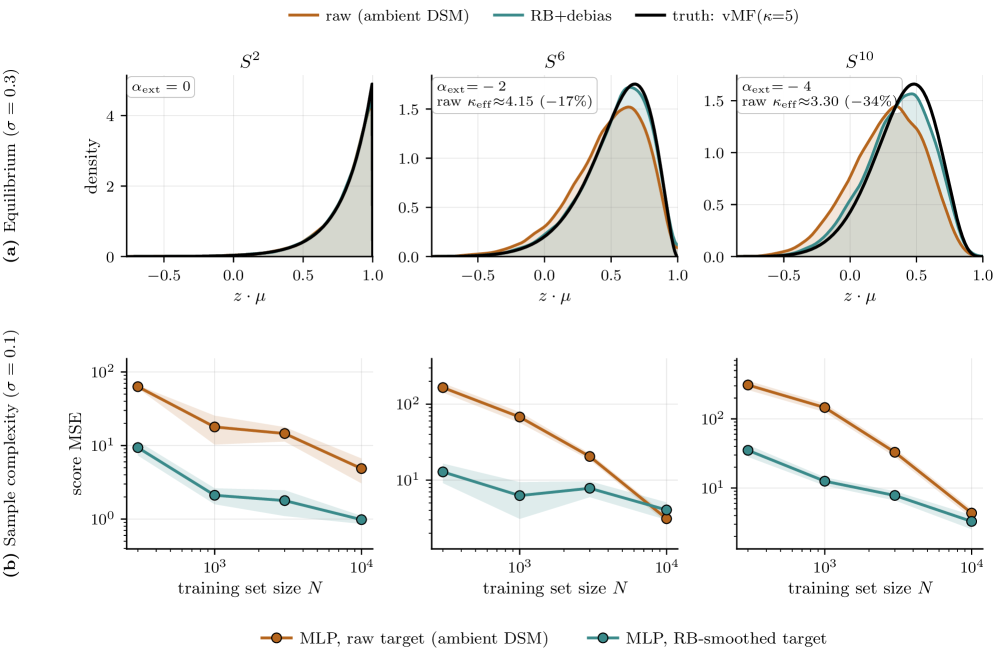
This explains a longstanding empirical observation: ambient diffusion models work surprisingly well on most test cases such as climate or weather data, which naturally live on .
- The partition function is the normalization constant that ensures the probability distribution integrates to unity. ↩
- To get some intuition for why this works, it's nice to consider a toy case: for a random variable distributed uniformly between 0 and 1, the probability of the event is exactly 0, but the probability of the event is nonzero. The idea here works similarly in principle. ↩
- Here, we just cover the absolute basics, but do Carmo [doC92] is a great reference. ↩
- Geodesics are paths with zero acceleration. ↩
- Concretely, is the metric-raised version of the Ricci tensor, which is itself a trace of the full Riemann curvature tensor. You can think of as an average of sectional curvatures of all 2-planes containing . ↩
- Strictly, you do need your score estimate to be reasonably accurate at the points where you're applying the correction. But you don't need access to itself, which is the usual obstacle. ↩
References
- [Efr11]Bradley Efron. "Tweedie’s Formula and Selection Bias". Journal of the American Statistical Association Vol. 106, pp. 1602 - 1614 2011. [link] ↩
- [Hyv05]Aapo Hyvärinen. "Estimation of non-normalized statistical models by score matching". 2005. [link] ↩
- [doC92]Manfredo Perdigão do Carmo. Riemannian Geometry. 1992. ↩